1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
|
import numpy as np
import matplotlib.pyplot as plt
learning_rate = 0.00003
def convolution(x, kernel, stride):
"""
二维平面上的卷积,padding为VALID
:param x: 被卷积的特征矩阵,是一个二维矩阵
:param kernel: 卷积核参数,为一个二维矩阵
:param stride: 步长信息,一个正整数
:return: 卷积之后的矩阵信息
"""
assert len(x.shape) == 2
assert len(kernel.shape) == 2
assert type(stride) is int
assert (x.shape[0] - kernel.shape[0]) % stride == 0 and (x.shape[1] - kernel.shape[1]) % stride == 0
result = np.zeros([(x.shape[0] - kernel.shape[0]) // stride + 1, (x.shape[1] - kernel.shape[1]) // stride + 1])
for i in range(0, x.shape[0] - kernel.shape[0] + 1, stride):
for j in range(0, x.shape[1] - kernel.shape[1] + 1, stride):
sum = 0
for p in range(kernel.shape[0]):
for k in range(kernel.shape[1]):
sum += x[i + p][j + k] * kernel[p][k]
result[i // stride][j // stride] = sum
return result
def padding_zeros(x, left_right, top_bottom):
"""
对矩阵的外围进行填补0的操作。
:param x: 一个二维矩阵
:param left_right: 一个长度为2的数组,分别表示左侧和右侧需要填补的0的层数
:param top_bottom: 一个长度为2的数组,分别表示上侧和下侧需要填补的0的层数
:return: 填补之后的矩阵
"""
assert len(x.shape) == 2
assert len(left_right) == 2 and len(top_bottom) == 2
new_x = np.zeros([top_bottom[0] + top_bottom[1] + x.shape[0], left_right[0] + left_right[1] + x.shape[1]])
new_x[top_bottom[0]: top_bottom[0] + x.shape[0], left_right[0]: left_right[0] + x.shape[1]] = x
return new_x
def insert_zeros(x, stride):
"""
在矩阵的每两个相邻元素之间插入一定数目的0
:param x: 一个二维矩阵
:param stride: 一个非负数
:return: 插入0之后的矩阵
"""
assert len(x.shape) == 2
assert type(stride) is int and stride >= 0
new_x = np.zeros([(x.shape[0] - 1) * stride + x.shape[0], (x.shape[1] - 1) * stride + x.shape[1]])
for i in range(x.shape[0]):
for j in range(x.shape[1]):
new_x[i * (stride + 1)][j * (stride + 1)] = x[i][j]
return new_x
def rotate_180_degree(x):
"""
将矩阵旋转180°,这一步主要是针对卷积核而言。
:param x: 需要被旋转的矩阵
:return: 旋转之后的矩阵
"""
assert len(x.shape) == 2
return np.rot90(np.rot90(x))
class conv(object):
def __init__(self, kernel, stride=1, bias=None):
"""
表示卷积的类
:param kernel: 卷积核参数,可以是一个整数,表示卷积核尺寸,也可以是一个二维的矩阵。
:param stride: 一个正整数,表示步长信息
:param bias: 偏置量,一个浮点数
"""
if type(kernel) is int:
self.kernel = np.random.normal(0, 1, [kernel, kernel])
self.kernel_size = kernel
elif type(kernel) is np.ndarray and len(kernel.shape) == 2:
assert kernel.shape[0] == kernel.shape[1]
self.kernel = kernel
self.kernel_size = kernel.shape[0]
self.bias = np.random.normal(0, 1) if bias is None else bias
self.stride = stride
self.x = None
def forward(self, x):
"""
前向传播的计算
:param x: 输入矩阵,是一个二维矩阵
:return: 经过卷积并加上偏置量之后的结果
"""
self.x = x
return convolution(x, self.kernel, stride=self.stride) + self.bias
def backward(self, error):
"""
卷积的反向传播过程
:param error: 接收到的上一层传递来的误差矩阵
:return: 应该传递给下一层的误差矩阵
"""
error_inserted = insert_zeros(error, stride=self.stride - 1)
error_ = padding_zeros(error_inserted,
[self.kernel_size - 1, self.kernel_size - 1],
[self.kernel_size - 1, self.kernel_size - 1])
kernel = self.kernel.copy()
kernel = rotate_180_degree(kernel)
error_ = convolution(error_, kernel, 1)
kernel_gradient = convolution(self.x, error_inserted, 1)
bias_gradient = np.sum(error_inserted)
self.kernel -= kernel_gradient * learning_rate
self.bias -= bias_gradient * learning_rate
return error_
class sigmoid(object):
def __init__(self):
self.x = None
def forward(self, x):
self.x = x
return 1.0/(1.0+np.exp(self.x))
def backward(self, error):
s = 1.0/(1.0+np.exp(self.x))
return error * s * (1 - s)
class relu(object):
def __init__(self):
self.x = None
def forward(self, x):
self.x = x
return np.maximum(x, 0)
def backward(self, error):
return error * (self.x > 0)
if __name__ == '__main__':
map = np.random.normal(1, 1, (20, 20))
print("*"*30)
print("feature map:")
print(np.round(map, 3))
kernel1 = np.array([[0, 0, 1], [0, 2, 0], [1, 0, 1]], dtype=np.float32)
kernel2 = np.array([[1, 0, 0, 1], [1, 0, 0, 1], [0, -1, -1, 0], [0, 1, 1, 0]], dtype=np.float32)
print("*"*30)
print("kernel 1:\n", kernel1)
print("*" * 30)
print("kernel 2:\n", kernel2)
conv1 = conv(kernel1, 1, 0)
map1 = conv1.forward(map)
conv2 = conv(kernel2, 2, 0)
target = conv2.forward(map1)
print("*"*30)
print("our target feature:\n", np.round(target, 3))
print("\nBuilding our model...")
conv1 = conv(3, 1, 0)
map1 = conv1.forward(map)
conv2 = conv(4, 2, 0)
map2 = conv2.forward(map1)
loss_collection = []
print("\nStart training ...")
for loop in range(2000):
loss_value = np.sum(np.square(map2 - target))
loss_collection.append(loss_value)
if loop % 100 == 99:
print(loop, ": ", loss_value)
error_ = 2 * (map2 - target)
error_ = conv2.backward(error_)
error_ = conv1.backward(error_)
map1 = conv1.forward(map)
map2 = conv2.forward(map1)
print("*"*30)
print("Our reconstructed map:")
print(map2)
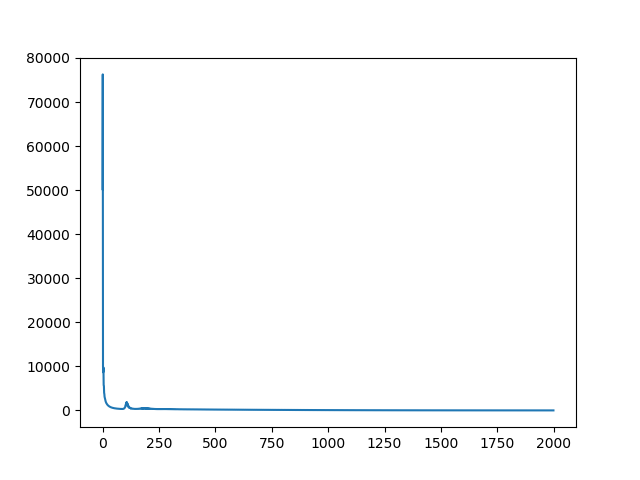
plt.plot(np.arange(len(loss_collection)), loss_collection)
plt.show()
|